.png)
How PKZIP Works in UNIX
This page provides a description of how PKZIP does its job. It is not necessary for you to know or understand the information presented here, any more than you need to know how your fuel injector works to drive a car. It is presented to help you feel more knowledgeable about the software.
Two Processes
PKZIP performs two functions: compression and archiving. Although the two ideas may seem related, they are actually completely separate.
- Compression is the process of representing a given piece of information with a smaller piece of information.
- Archiving is the process of combining many files into a single unit, usually along with vital information about each file.
Compression
The actual process used by PKZIP for its compression is too complex to explain in detail. Instead, some of the general principles behind information theory and compression are explained.
To understand data compression, you need to understand two ideas: Information Content and Binary Coding.
Information Content
Everything in your computer, everything you ever read, is "information." The more complex a message is, the higher the information content. The less complex, the less "random" a message is, the lower the information content.
When we talk about information in this context, we're not comparing the amount of information contained in a news article compared to an entertainment show on television. Think about it more in terms of combinations of letters, numbers and punctuation.
If a message contains a low amount of information, it should be possible to represent it in a smaller amount of space. Look at this page, for example. How much of the page is white space with no letters (information) on it? If you took away all of the white space this page would be significantly smaller. How many times are the words "the", "information" and "compression" on this page? If you could replace each of these words with something smaller, you would save a significant amount of space.
The more frequently the same group of symbols (in this case, letters) appears, the lower the information content of the message.
The field of "Information Theory" uses the term entropy to describe the "true" information content of a message. Formulas can be used to determine the entropy of a message. The idea behind data compression is to derive a new smaller message from a larger original message, while maintaining the entropy of the original message.
As a simple example, consider this sentence:
she sells sea shells by the sea shore
This sentence is 37 characters long, including spaces. The spaces cannot be simply thrown away as the meaning of the original message would be lost.
There are obvious patterns to the sentence. The combination 'se' appears three times, 'sh' three times, and 'lls' twice. In fact, the 'se' pairs all have a space in front of them, so these can be ' se'.
she sells sea shells by the sea shore
We can replace each of these patterns with a single character:
#=" se"
$="sh"
%="lls"
the first replacement string includes a space at the beginning. If we reproduce the sentence with these symbols, it now looks like:
$e#%#a $e% by the#a $ore
The new representation is 24 characters long; this is a saving of 13 characters, or 36%.
Binary Data Representation
All information used, stored, and processed by computers is represented by two values, zero and one. Everything that you see on your screen, everything stored on disk, is represented by combinations of zero and one.
You can think of it as a sort of Morse code. In Morse code there are also only two values, dot and dash. When a computer stores a character, it uses a combination of eight zeros and ones.
Having eight positions in which to store a zero or one gives the computer 256 different possible combinations. You arrive at this number of combinations in this way:
If you have one coin, it can be in either of two positions: Heads(0) or Tails(1)
0 or 1
If you have two coins, there are four possible combinations:
00, 11, 10, 01
If you have three coins, there are eight possible combinations:
000, 001, 010, 011, 100, 101, 110, 111
As you can see, each time you add another coin (binary digit), the number of possible combinations doubles: 2, 4, 8, 16, 32, 64, 128, 256.
The computer uses eight binary digits to get 256 possible values. These values are mapped onto a table called ASCII (American Standard Code for Information Interchange). Each different combination has a particular character that is mapped to it, such as a letter, number or symbol. Each of these positions of 0 or 1 is called a bit.
she sells sea shells by the sea shore
The sample message above would be represented by 296 bits (37x8 bits).
If we follow standard ASCII, we have 256 different symbols being represented for our use. The sample sentence we are using only contains alphabetical characters, and only 11 of them at that. If we only need 11 different values, we could use a lower number of bits per character.
The closest value to 11 using binary combinations is 16 combinations, using 4 bits per character. If we wrote a new table of our own using four bits per character, and used it to represent the message, we would use only 98 bits. This would be half as many bits, a considerable savings.
We can do better!
It is possible to have binary codes of varying length. To do this we must use codes with unique values that are not repeated as the beginning of another code. In this way, we can find the codes in a long stream of zeros and ones.
If the codes were not constructed to have unique beginnings, it would not be possible to find each individual code within a long stream of zeroes and ones.
There are many types of coding techniques that produce codes of varying length, based upon symbol frequency. Some well-known coding schemes are Huffman and Shannon-Fanno. PKZIP uses Huffman encoding. The scheme is too complex to document here fully (you can find a lengthy description and a link to Huffman's original paper at Wikipedia), however, we will discuss some rudiments of encoding. It is necessary for you to understand the principles described here.
A table of variable length codes for 11 symbols would look like this:
11 | 1101 |
110 | 0100 |
101 | 1000 |
001 | 01010 |
1011 | 00000 |
0010 |
As you can see, the codes are getting longer and longer. Because of this, we will get the best results if we map the shortest code to the most common symbol in the message. If you know Morse code, or have occasion to look at it, you will notice that frequent characters, such as 'e', 't', 's' and so on have shorter codes assigned to them. Morse code tends to be about 25% more efficient because of this than it would have been had the codes been assigned at random.
A useful idea here is to allow a symbol to be not only a character, but also a group of characters.
Using the common patterns found in the first analysis of the message, we can map the following table:
Occurrences | Symbol | New Code | Bits in Message |
|---|---|---|---|
4 | e | 11 | 8 |
4 | (space) | 110 | 12 |
3 | 'se' | 001 | 9 |
3 | sh | 101 | 9 |
2 | lls | 1011 | 8 |
2 | a | 0010 | 8 |
1 | b | 1101 | 4 |
1 | y | 0100 | 4 |
1 | t | 1000 | 4 |
1 | o | 01010 | 5 |
1 | r | 00000 | 5 |
Our new coding scheme can represent the message with only 74 bits. This is a savings of 222 bits from the 296 bits used in the "natural" encoding. This is one quarter of the original message size.
One important factor that would affect a real situation is the table we are using. In order for the data to be re-created from the "compressed" representation, we must include a copy of the table used to encode the data.
This can be a seriously limiting factor. If the data is too complex, or the encoding scheme too inefficient, the table used can be as big as the space saved by the encoding. In the worst cases, an attempt to re-encode the message using a table results in the encoded message plus the table being larger than the original message.
This is why data which uses a low number of symbols and frequently repeated combinations of symbols, such as a text file, compresses well. Complex, highly random data, such as the information representing a program on disk is difficult to encode efficiently, and therefore compresses less.
Speed vs. Size
Searching for these patterns, and determining an efficient way to encode the data, takes a lot of computer power and time. The more time taken to analyze the data the better the compression will be. To get more speed, you must sacrifice some level of compression.
There are other steps and methods used in powerful compression schemes such as those used by PKWARE products. Hopefully this explanation gives you a better understanding of what happens when PKZIP compresses data.
Archiving
Programs usually rely heavily on associated data files, or may actually consist of several related programs. Some programs may require dozens or even hundreds of files.
In the dawn of the PC age, people wanted a way to keep all of these associated files in one location. "Library" programs were created to take a number of files and group them together into a single file. This made them easier to find, easier to store, and much easier to send to someone by modem. It makes much more sense to be able to send someone a single "package" instead of many files. If you forget a file, all sorts of problems arise.
These programs were the birth of Archiving. For a single file to hold many files, information about each file also had to be stored in the archive. This information could then be used by the archival software to locate a file and pull it out, or to list information about the files contained within an archive.
Compression was first available as a utility that would take a single file and produce its compressed equivalent. People began to group files together with a Library program and then compress the archive file.
The next and obvious step in this process was to combine the two ideas. Compress the files and archive them. This made storage very simple; the compression was no longer a separate step and could be taken for granted as part of the archiving process.
PKZIP is the second generation of these programs. PKZIP can not only compress and archive files, but also stores a great deal of vital information about the files. PKZIP even stores directory structures.
How PKZIP builds a .ZIP File
When you specify a PKZIP command line, PKZIP goes through several steps:
- Parsing the command line.
- Reserves the memory it will need to perform the compression, archiving and buffering.
- PKZIP looks for a .ZIP file with the same name as the one you specified on the command line. If it finds one, PKZIP reads the information on the files that it contains.
- PKZIP then performs the requested action; it builds a new .ZIP file if none was found.
- PKZIP reads the information from the command line specifying what files it is supposed to take, what files it should not take, and if there is an exclude command.
- If a @list file is used, PKZIP reads it, then checks for which files exist. If a pattern is specified in the @list file, PKZIP generates a list of the files which match this pattern.
- If directory recursion has been specified with the recurse option, PKZIP next looks for any subdirectories. If it locates subdirectories it goes into them and looks for any files matching the files specified on the command line or in the @list file. If PKZIP finds subdirectories in the subdirectories, it repeats the process. It will continue this process until it finds no additional subdirectories.
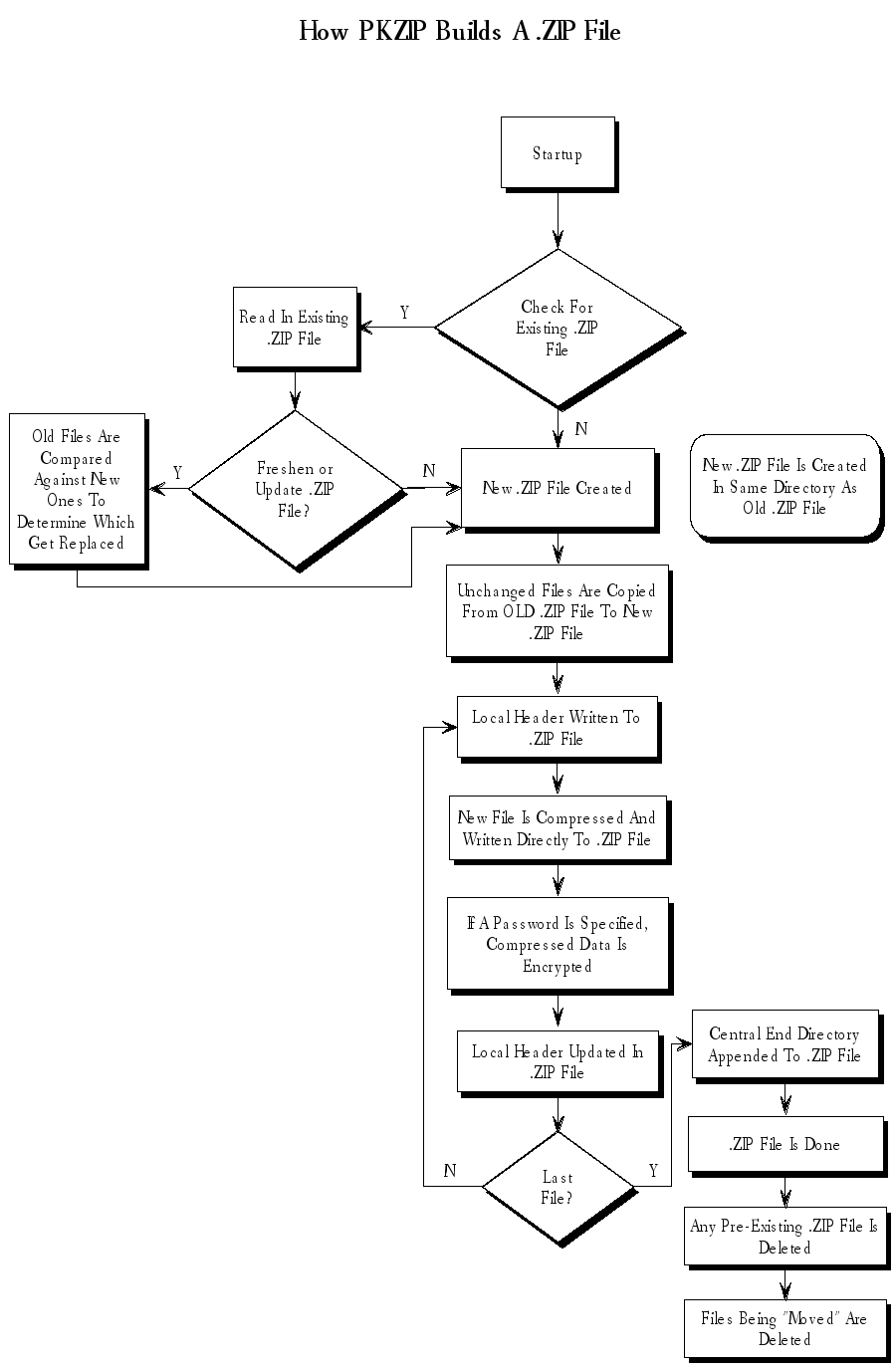
Now PKZIP has a list in memory of all the files it should take. The files specified for exclusion are now compared against this list, and any that match are removed. If after this step is complete the list in memory is empty, PKZIP finishes with a "Nothing to do!" message.
Now PKZIP reads-in each file, one at a time, and compresses it. When it is finished compressing a file, it adds it to the .ZIP file being created.
As PKZIP reads each file, it computes a CRC value for it. This CRC value is stored as part of the information concerning the file.
CRC
This is an acronym for Cyclic Redundancy Check. When a CRC is performed, the data making up a file is passed through an algorithm. The algorithm computes a value based upon the contents resulting in an eight-digit hexadecimal number representing the value of the file.
If even a single bit of a file is altered, and the CRC is performed again, the resulting CRC value will be different. By using a CRC value, it can be determined that there is an exact match for a particular file.
PKZIP calculates a CRC value for the original file before it is compressed. This value is then stored with a file in the .ZIP file. When a file is extracted it calculates a CRC value for the extracted data and compares it against the original CRC value. If the data has been damaged or altered, PKZIP can recognize and report this.
- When PKZIP adds the compressed file to the .ZIP file, it first writes out a "Local Header" about the file. This Header contains useful information about the file, including:
- The minimum version of PKZIP needed to extract this file
- The compression method used on this file
- File time
- File date
- The CRC value
- The size of the compressed data
- The uncompressed size of the file
- The file name
- After PKZIP has written all of the files to disk, it appends the "Central Directory" to the end of the .ZIP file. This Directory contains the same information as the Local Header for every file, as well as additional information. Some of this additional information includes:
- The version of PKZIP that created the file
- A comment about each file (if any)
- File attributes (Hidden, Read Only, System)
- Extended Attributes (if specified)
Deleting Files from a .ZIP File
PKZIP deletes files from a .ZIP file in the following manner:
- PKZIP reads in the names of all the files contained in the .ZIP file.
- PKZIP compares this list against the files you wish to delete.
- Whatever files remain are moved into a new .ZIP file.
- The original .ZIP file is superseded by a newer version of the .ZIP file.
This means that in order to delete files from a .ZIP file, you must have enough disk space to hold both the original .ZIP file and the new .ZIP file that lacks the deleted files.
Adding to an Existing .ZIP File
Adding files to a .ZIP file is the same as creating a .ZIP file, but with one difference. Before PKZIP begins to add files, it first reads in the files that were in the existing .ZIP file. These old files and the new files are then both written out to a new .ZIP file, the old files being superseded by the new .ZIP files. This means that there must be enough free space for the old .ZIP file as well as the new .ZIP file to co-exist.